无需维护复杂的爬虫集群。IPWeb提供面向开发者的爬虫API服务,用于公开网络内容访问。内置动态渲染引擎,支持全球站点网页内容提取,并可输出 Markdown、CSV、HTML 或 JSON 格式,便于系统集成与应用开发。
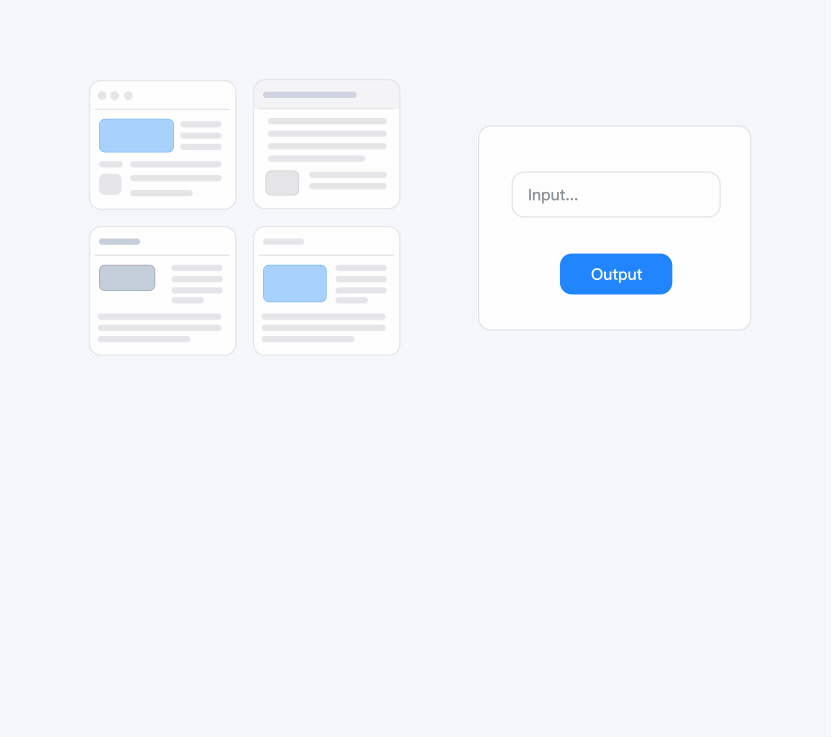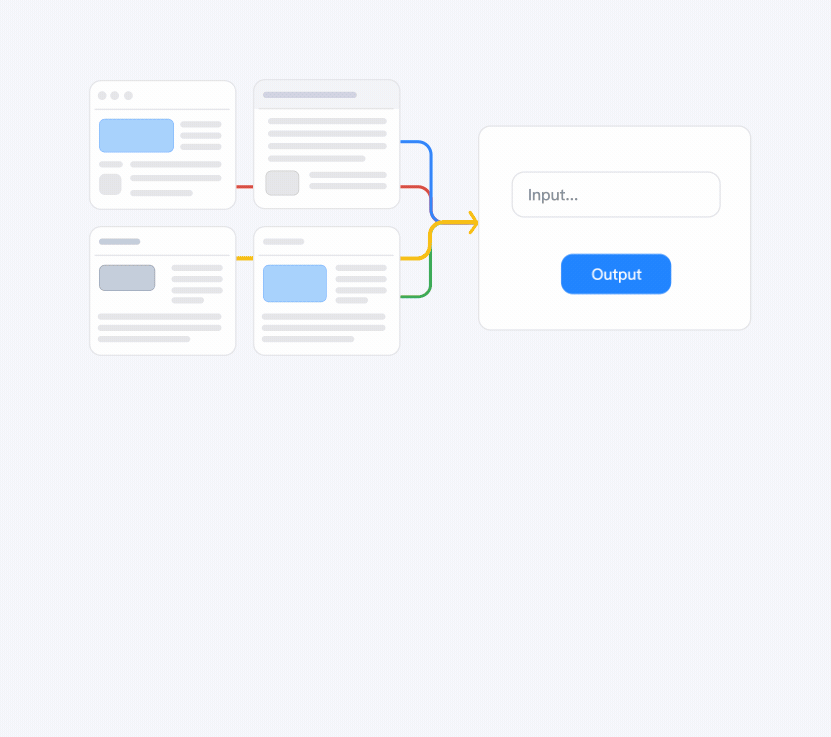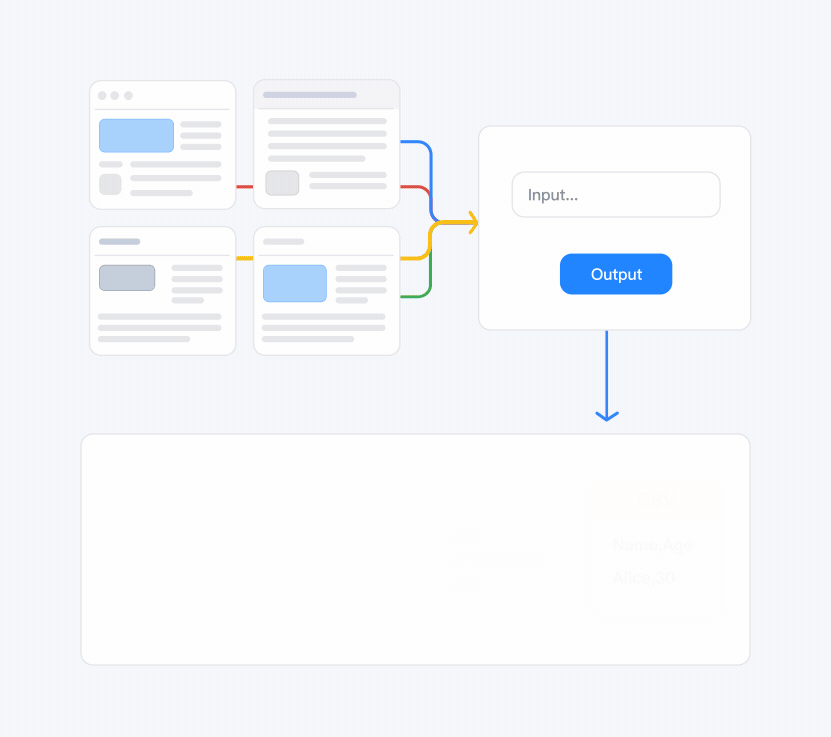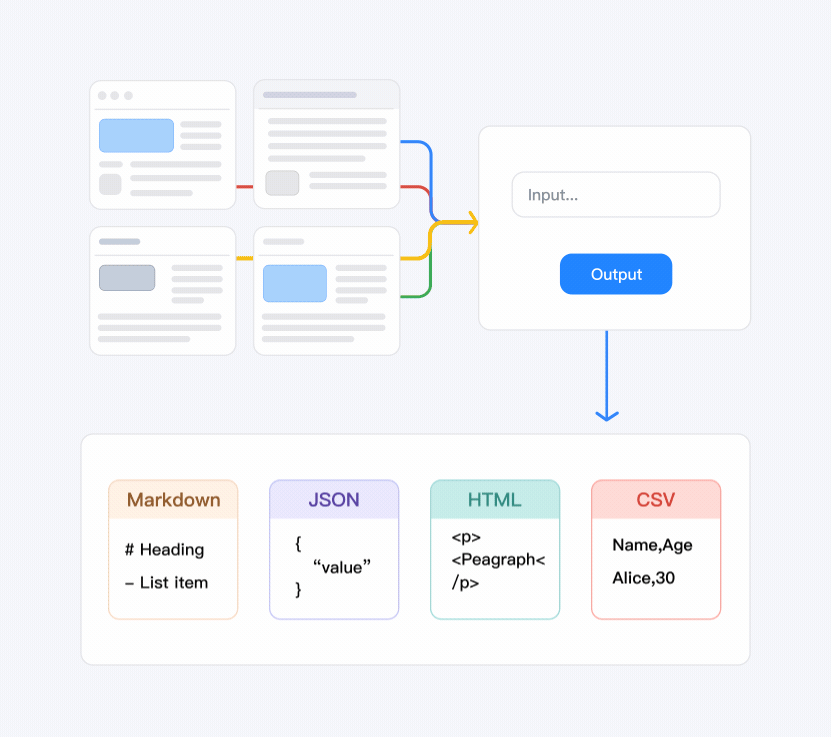
极速集成
兼容 Python、Node.js 等主流开发语言。基于标准 RESTful 接口设计,无需维护复杂脚本即可访问网页内容,并返回结构化数据,便于快速集成到业务系统。

多地区网络资源
提供覆盖多个地区的数据中心网络资源,支持按区域选择网络出口,满足不同应用场景的访问需求。

动态页面访问
支持现代网页结构访问,可处理常见的动态加载页面,适用于复杂前端网站内容获取场景。

智能内容解析
内置网页内容解析能力,可将网页内容转换为结构化数据格式,例如 JSON、HTML 或 Markdown,方便系统处理。

稳定请求管理
内置请求管理机制,可在复杂网络环境下保持稳定访问,适用于长期运行的应用任务。

自动化任务支持
支持通过 API 创建访问任务,并可结合定时任务运行,便于构建自动化数据处理流程。

云端任务管理
支持任务调度与结果推送,可通过 Webhook 或 API 将处理结果发送至业务系统或数据库。
从规模超大、高度合乎道德准则的提供商处购买
立即注册,首次充值,即可获赠相应奖励,最高可达2K请求。

体验套餐
按月付费
低门槛,随用随付
包含250K请求
$250.00 月付计划
非常适合中小团队
包含750K请求
$600.00 月付计划
专为数据运营团队定制
包含1.9M请求
$1,400.00 月付计划
适合企业级数据平台
需要千万级请求或定制方案?
满足多样化的网页爬虫 API 使用场景
动态抓取
支持对HTML、JSON、XML 等多格式数据的抓取。无论是静态网页还是动态加载的复杂页面,均可自定义字段规则,一键获取结构化数据。
内容聚合
聚合全球新闻、博客与公开信息源,通过智能数据处理将网页内容转化为结构化数据,支持商业分析与市场洞察。
社媒分析
高效获取 Twitter, Reddit, TikTok 等平台的公开贴文与评论数据。通过集成式交互解析保障获取成功率,赋能市场趋势的敏捷决策。
电商分析
支持亚马逊、eBay 及独立站的高并发任务。实时分析SKU 价格变动与库存状态,利用住宅代理模拟真实消费者访问,确保抓取到的价格真实准确。
排名追踪
精准获取 Google、Bing 等搜索引擎的本地化搜索结果 (SERP)。支持指定国家或城市级别的地理位置,真实还原不同地区用户的搜索排名与广告展现情况。

LinkedIn 数据获取
批量获取公开 Profile 信息,覆盖姓名、职位、公司等 50+ 核心字段。支持精准 B2B 客户线索挖掘,助力招研与全球市场拓展。

电商数据分析
覆盖 Amazon、Shopee等主流平台。实时分析商品 ASIN、价格、销量排名与评论反馈,为选品决策与竞品分析提供结构化数据支持。

社交媒体解析
追踪 Instagram/Twitter 帖子与互动数据。实时分析品牌声量、粉丝情绪与趋势,为社交媒体营销提供可视化的数据洞察。
诚信
IPWeb专注于代理网络与数据访问基础设施建设,服务全球工程团队、数据公司与 AI 企业。 所有代理资源遵循合规获取与使用原则,支持企业级安全与长期业务发展。

合规
IPWeb 的代理服务严格遵守 GDPR、CCPA 等全球领先的数据隐私保护法律法规,并由 ISO 信息安全体系认证提供保障。我们致力于确保企业数据交互过程的完全合规性与隐私权保护,帮助企业合法、合规地开展全球公开商业数据收集与市场研究。
